publications
publications by categories in reversed chronological order. generated by jekyll-scholar. more publications can be found on my Google Scholar page
2026
- LOOCAlleviating Contextual Misguidance: Response-Aware Prompt Compression for Long-Context Question AnsweringHaoyuan Wang, Zhen Wang, Wenmeng Zhou, and Yang DengIEEE Transactions on Audio, Speech and Language Processing, 2026
The ability of Large Language Models (LLMs) to accurately process long contexts is crucial for many real-world applications. However, despite recent advancements in extending context windows, we find that contemporary LLMs still suffer from the phenomenon known as “Lost In The Middle”, where LLMs fail to accurately retrieve information located centrally within long-context prompts. Our analysis reveals that this failure is often caused by “contextual misguidance”, where query-relevant yet non-grounding segments distract the model. To mitigate this issue, we introduce Leave-One-Out Compression (LOOC), a novel response-aware prompt compression method. LOOC quantifies the influence of each prompt segment on the model outputs and then reconstructs a shorter, concentrated prompt using only the most influential segments. This new prompt is then used to generate a more accurate final answer. We evaluate LOOC on several long-context benchmarks, showing its superior performance and robustness across models. Notably, it improves performance by 15.14% for Qwen2.5-7B in the scenario where the model is most prone to get distracted, highlighting its effectiveness in mitigating contextual misguidance.
@article{LOOC, dimensions = {true}, author = {Wang, Haoyuan and Wang, Zhen and Zhou, Wenmeng and Deng, Yang}, journal = {IEEE Transactions on Audio, Speech and Language Processing}, title = {Alleviating Contextual Misguidance: Response-Aware Prompt Compression for Long-Context Question Answering}, year = {2026}, volume = {}, number = {}, pages = {1-12}, keywords = {Context modeling;Computational modeling;Grounding;Analytical models;Speech processing;Accuracy;Transformers;Large language models;Electronic mail;Data models;Context attribution;large language models;long context;prompt compression}, doi = {10.1109/TASLPRO.2026.3675784} }
2025
- SAMAGSAMAG: Structure-Aware Multi-Agent Graph Generation with Large Language ModelsJingcheng Cen, Jiarui Ji, Zhen Wang, Zhewei Wei, and 2 more authorsIn 2025 IEEE International Conference on Big Data (BigData), 2025
Graph generation is fundamental in network science and graph machine learning, yet existing rule-based and deep learning models either miss fine-grained structures or remain static and data-hungry, while recent LLM-based multi-agent methods suffer from structural myopia by ignoring graph topology. We propose a Structure-Aware Multi-Agent-based Graph generation framework (SAMAG), which integrates structureaware information retrieval and agent orchestration to combine semantic and topological context, enabling agents to form realistic communities and yield temporally coherent interaction patterns. Experiments across various domains demonstrate that SAMAG consistently achieves state-of-the-art graph-level fidelity and outperforms previous LLM-based methods in communitylevel fidelity, while in the inductive setting improves GNN node classification accuracy by 18.5% on average over the bestperformed baseline. SAMAG establishes the first structure-aware LLM-based framework, advancing both the fidelity and transferability of synthesized graphs.
@inproceedings{SAMAG, dimensions = {true}, author = {Cen, Jingcheng and Ji, Jiarui and Wang, Zhen and Wei, Zhewei and Li, Yaliang and Ding, Bolin}, booktitle = {2025 IEEE International Conference on Big Data (BigData)}, title = {SAMAG: Structure-Aware Multi-Agent Graph Generation with Large Language Models}, year = {2025}, volume = {}, number = {}, pages = {488-499}, keywords = {Deep learning;Accuracy;Network topology;Large language models;Scalability;Semantics;Information retrieval;Topology;Faces;Multi-agent systems;Multi-agent System;Large Language Model;Graph Generation}, doi = {10.1109/BigData66926.2025.11402080} } - RARB
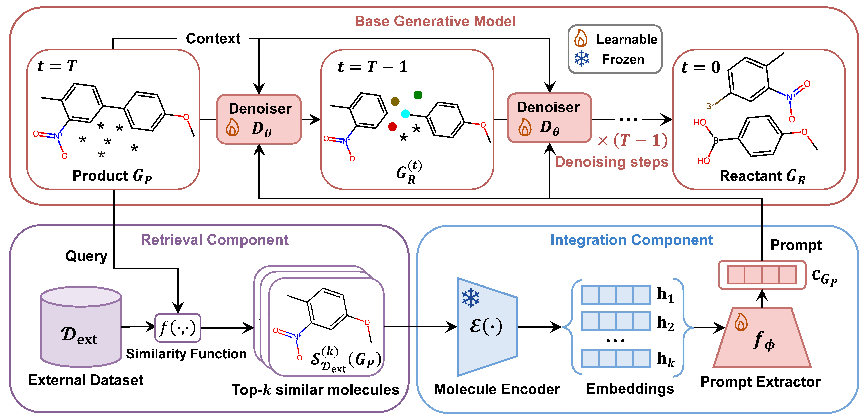 Advancing Retrosynthesis with Retrieval-Augmented Graph GenerationAnjie Qiao*, Zhen Wang*, Jiahua Rao, Yuedong Yang, and 1 more authorProceedings of the AAAI Conference on Artificial Intelligence, Apr 2025* Equal contribution
Advancing Retrosynthesis with Retrieval-Augmented Graph GenerationAnjie Qiao*, Zhen Wang*, Jiahua Rao, Yuedong Yang, and 1 more authorProceedings of the AAAI Conference on Artificial Intelligence, Apr 2025* Equal contributionDiffusion-based molecular graph generative models have achieved significant success in template-free, single-step retrosynthesis prediction. However, these models typically generate reactants from scratch, often overlooking the fact that the scaffold of a product molecule typically remains unchanged during chemical reactions. To leverage this useful observation, we introduce a retrieval-augmented molecular graph generation framework. Our framework comprises three key components: a retrieval component that identifies similar molecules for the given product, an integration component that learns valuable clues from these molecules about which part of the product should remain unchanged, and a base generative model that is prompted by these clues to generate the corresponding reactants. We explore various design choices for critical and under-explored aspects of this framework and instantiate it as the Retrieval-Augmented RetroBridge (RARB). RARB demonstrates state-of-the-art performance on standard benchmarks, achieving a 14.8% relative improvement in top-1 accuracy over its base generative model, highlighting the effectiveness of retrieval augmentation. Additionally, RARB excels in handling out-of-distribution molecules, and its advantages remain significant even with smaller models or fewer denoising steps. These strengths make RARB highly valuable for real-world retrosynthesis applications, where extrapolation to novel molecules and high-throughput prediction are essential.
@article{RARB, dimensions = {true}, note = {* Equal contribution}, title = {Advancing Retrosynthesis with Retrieval-Augmented Graph Generation}, volume = {39}, url = {https://ojs.aaai.org/index.php/AAAI/article/view/34203}, doi = {10.1609/aaai.v39i19.34203}, number = {19}, journal = {Proceedings of the AAAI Conference on Artificial Intelligence}, author = {Qiao, Anjie and Wang, Zhen and Rao, Jiahua and Yang, Yuedong and Wei, Zhewei}, year = {2025}, month = apr, pages = {20004-20013} }
2024
- GNSLExploring Neural Scaling Law and Data Pruning Methods For Node Classification on Large-scale GraphsZhen Wang, Yaliang Li, Bolin Ding, Yule Li, and 1 more authorIn Proceedings of the ACM Web Conference 2024, Singapore, Singapore, Apr 2024
Recently, how the model performance scales with the training sample size has been extensively studied for large models on vision and language related domains. Nevertheless, the ubiquitous node classification tasks on web-scale graphs were ignored, where the traits of these tasks, such as non-IIDness and transductive setting, are likely to cause different scaling laws and motivate novel techniques to beat the law. Therefore, we first explore the neural scaling law for node classification tasks on three large-scale graphs. Then, we benchmark several state-of-the-art data pruning methods on these tasks, not only validating the possibility of improving the original unsatisfactory power law but also gaining insights into a hard-and-representative principle on picking an effective subset of training nodes. Moreover, we leverage the transductive setting to propose a novel data pruning method, which instantiates our principle in a test set-targeted manner. Our method consistently outperforms related methods on all three datasets. Meanwhile, we utilize a PAC-Bayesian framework to analyze our method, extending prior results to account for both hardness and representativeness. In addition to a promising way to ease GNN training on web-scale graphs, our study offers knowledge of the relationship between training nodes and GNN generalization.
@inproceedings{GNSL, dimensions = {true}, author = {Wang, Zhen and Li, Yaliang and Ding, Bolin and Li, Yule and Wei, Zhewei}, title = {Exploring Neural Scaling Law and Data Pruning Methods For Node Classification on Large-scale Graphs}, year = {2024}, isbn = {9798400701719}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3589334.3645571}, doi = {10.1145/3589334.3645571}, booktitle = {Proceedings of the ACM Web Conference 2024}, pages = {780–791}, numpages = {12}, keywords = {data pruning, graph neural networks, neural scaling laws}, location = {Singapore, Singapore}, series = {WWW '24} } - Coaformer
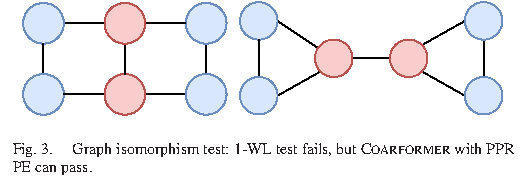 When Transformer Meets Large Graphs: An Expressive and Efficient Two-View ArchitectureWeirui Kuang*, Zhen Wang*, Zhewei Wei, Yaliang Li, and 1 more authorIEEE Transactions on Knowledge and Data Engineering, Apr 2024* Equal contribution
When Transformer Meets Large Graphs: An Expressive and Efficient Two-View ArchitectureWeirui Kuang*, Zhen Wang*, Zhewei Wei, Yaliang Li, and 1 more authorIEEE Transactions on Knowledge and Data Engineering, Apr 2024* Equal contributionThe successes of applying Transformer to graphs have been witnessed on small graphs (e.g., molecular graphs), yet two barriers prevent its adoption on large graphs (e.g., citation networks). First, despite the benefit of the global receptive field, enormous distant nodes might distract the necessary attention of each target node from its neighborhood. Second, training a Transformer model on large graphs is costly due to the node-to-node attention mechanism’s quadratic computational complexity. To break down these barriers, we propose a two-view architecture Coarformer, wherein a GNN-based module captures fine-grained local information from the original graph, and a Transformer-based module captures coarse yet long-range information on the coarse graph. We further design a cross-view propagation scheme so that these two views can enhance each other. Our graph isomorphism analysis shows the complementary natures of GNN and Transformer, justifying the motivation and design of Coarformer. We conduct extensive experiments on real-world datasets, where Coarformer surpasses any single-view method that solely applies a GNN or Transformer. As an ablation, Coarformer outperforms straightforward combinations of a GNN model and a Transformer-based model, verifying the effectiveness of our coarse global view and the cross-view propagation scheme. Meanwhile, Coarformer consumes the least runtime and GPU memory than those combinations.
@article{Coaformer, dimensions = {true}, note = {* Equal contribution}, author = {Kuang, Weirui and Wang, Zhen and Wei, Zhewei and Li, Yaliang and Ding, Bolin}, journal = {IEEE Transactions on Knowledge and Data Engineering}, title = {When Transformer Meets Large Graphs: An Expressive and Efficient Two-View Architecture}, year = {2024}, volume = {36}, number = {10}, pages = {5440-5452}, keywords = {Transformers;Encoding;Computer architecture;Graph neural networks;Symbols;Task analysis;Smoothing methods;Graph neural network;representation learning;transformer}, doi = {10.1109/TKDE.2024.3381125} }
2023
- FedHPO-Bench
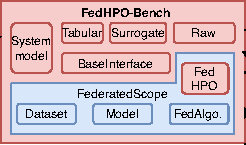 FedHPO-Bench: A Benchmark Suite for Federated Hyperparameter OptimizationZhen Wang*, Weirui Kuang*, Ce Zhang, Bolin Ding, and 1 more authorIn Proceedings of the 40th International Conference on Machine Learning, 23–29 jul 2023* Equal contribution
FedHPO-Bench: A Benchmark Suite for Federated Hyperparameter OptimizationZhen Wang*, Weirui Kuang*, Ce Zhang, Bolin Ding, and 1 more authorIn Proceedings of the 40th International Conference on Machine Learning, 23–29 jul 2023* Equal contributionResearch in the field of hyperparameter optimization (HPO) has been greatly accelerated by existing HPO benchmarks. Nonetheless, existing efforts in benchmarking all focus on HPO for traditional learning paradigms while ignoring federated learning (FL), a promising paradigm for collaboratively learning models from dispersed data. In this paper, we first identify some uniqueness of federated hyperparameter optimization (FedHPO) from various aspects, showing that existing HPO benchmarks no longer satisfy the need to study FedHPO methods. To facilitate the research of FedHPO, we propose and implement a benchmark suite FedHPO-Bench that incorporates comprehensive FedHPO problems, enables flexible customization of the function evaluations, and eases continuing extensions. We conduct extensive experiments based on FedHPO-Bench to provide the community with more insights into FedHPO. We open-sourced FedHPO-Bench at https://github.com/alibaba/FederatedScope/tree/master/benchmark/FedHPOBench.
@inproceedings{FedHPO-Bench, dimensions = {true}, note = {* Equal contribution}, title = {{F}ed{HPO}-Bench: A Benchmark Suite for Federated Hyperparameter Optimization}, author = {Wang, Zhen and Kuang, Weirui and Zhang, Ce and Ding, Bolin and Li, Yaliang}, booktitle = {Proceedings of the 40th International Conference on Machine Learning}, pages = {35908--35948}, year = {2023}, editor = {Krause, Andreas and Brunskill, Emma and Cho, Kyunghyun and Engelhardt, Barbara and Sabato, Sivan and Scarlett, Jonathan}, volume = {202}, series = {Proceedings of Machine Learning Research}, month = {23--29 Jul}, publisher = {PMLR}, url = {https://proceedings.mlr.press/v202/wang23n.html} } - FS
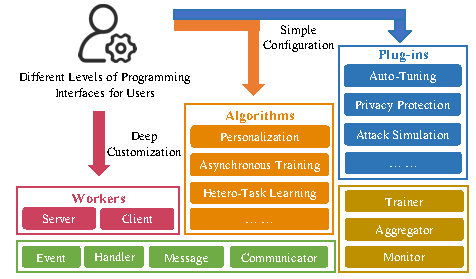 FederatedScope: A Flexible Federated Learning Platform for HeterogeneityYuexiang Xie*, Zhen Wang*, Dawei Gao, Daoyuan Chen, and 5 more authorsProc. VLDB Endow., Jan 2023* Equal contribution
FederatedScope: A Flexible Federated Learning Platform for HeterogeneityYuexiang Xie*, Zhen Wang*, Dawei Gao, Daoyuan Chen, and 5 more authorsProc. VLDB Endow., Jan 2023* Equal contributionAlthough remarkable progress has been made by existing federated learning (FL) platforms to provide infrastructures for development, these platforms may not well tackle the challenges brought by various types of heterogeneity. To fill this gap, in this paper, we propose a novel FL platform, named FederatedScope, which employs an event-driven architecture to provide users with great flexibility to independently describe the behaviors of different participants. Such a design makes it easy for users to describe participants with various local training processes, learning goals and backends, and coordinate them into an FL course with synchronous or asynchronous training strategies. Towards an easy-to-use and flexible platform, FederatedScope enables rich types of plug-in operations and components for efficient further development, and we have implemented several important components to better help users with privacy protection, attack simulation and auto-tuning. We have released FederatedScope at https://github.com/alibaba/FederatedScope to promote academic research and industrial deployment of federated learning in a wide range of scenarios.
@article{FS, dimensions = {true}, note = {* Equal contribution}, author = {Xie, Yuexiang and Wang, Zhen and Gao, Dawei and Chen, Daoyuan and Yao, Liuyi and Kuang, Weirui and Li, Yaliang and Ding, Bolin and Zhou, Jingren}, title = {FederatedScope: A Flexible Federated Learning Platform for Heterogeneity}, year = {2023}, issue_date = {January 2023}, publisher = {VLDB Endowment}, volume = {16}, number = {5}, issn = {2150-8097}, url = {https://doi.org/10.14778/3579075.3579081}, doi = {10.14778/3579075.3579081}, journal = {Proc. VLDB Endow.}, month = jan, pages = {1059–1072}, numpages = {14} } - BASEBASE: Bridging the Gap between Cost and Latency for Query OptimizationXu Chen, Zhen Wang, Shuncheng Liu, Yaliang Li, and 5 more authorsProc. VLDB Endow., Apr 2023
Some recent works have shown the advantages of reinforcement learning (RL) based learned query optimizers. These works often use the cost (i.e., the estimation of cost model) or the latency (i.e., execution time) as guidance signals for training their learned models. However, cost-based learning underperforms in latency and latency-based learning is time-intensive. In order to bypass such a dilemma, researchers attempt to transfer a learned value network from the cost domain to the latency domain. We recognize critical insights in cost/latency-based training, prompting us to transfer the reward function rather than the value network. Based on this idea, we propose a two-stage RL-based framework, BASE, to bridge the gap between cost and latency. After learning a policy based on cost signals in its first stage, BASE formulates transferring the reward function as a variant of inverse reinforcement learning. Intuitively, BASE learns to calibrate the reward function and updates the policy regarding the calibrated one in a mutually-improved manner. Extensive experiments exhibit the superiority of BASE on two benchmark datasets: Our optimizer outperforms traditional DBMS, using 30% less training time than SOTA methods. Meanwhile, our approach can enhance the efficiency of other learning-based optimizers.
@article{BASE, dimensions = {true}, author = {Chen, Xu and Wang, Zhen and Liu, Shuncheng and Li, Yaliang and Zeng, Kai and Ding, Bolin and Zhou, Jingren and Su, Han and Zheng, Kai}, title = {BASE: Bridging the Gap between Cost and Latency for Query Optimization}, year = {2023}, issue_date = {April 2023}, publisher = {VLDB Endowment}, volume = {16}, number = {8}, issn = {2150-8097}, url = {https://doi.org/10.14778/3594512.3594525}, doi = {10.14778/3594512.3594525}, journal = {Proc. VLDB Endow.}, month = apr, pages = {1958–1966}, numpages = {9} }
2022
- NW-GNN
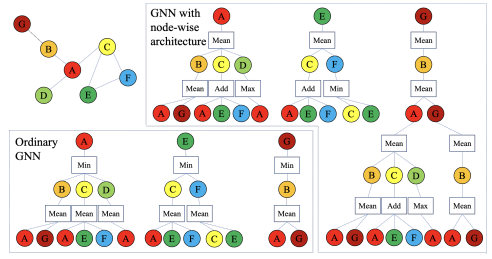 Graph Neural Networks with Node-wise ArchitectureZhen Wang, Zhewei Wei, Yaliang Li, Weirui Kuang, and 1 more authorIn Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington DC, USA, Apr 2022
Graph Neural Networks with Node-wise ArchitectureZhen Wang, Zhewei Wei, Yaliang Li, Weirui Kuang, and 1 more authorIn Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington DC, USA, Apr 2022Recently, Neural Architecture Search (NAS) for GNN has received increasing popularity as it can seek an optimal architecture for a given new graph. However, the optimal architecture is applied to all the instances (i.e., nodes, in the context of graph) equally, which might be insufficient to handle the diverse local patterns ingrained in a graph, as shown in this paper and some very recent studies. Thus, we argue the necessity of node-wise architecture search for GNN. Nevertheless, node-wise architecture cannot be realized by trivially applying NAS methods node by node due to the scalability issue and the need for determining test nodes’ architectures. To tackle these challenges, we propose a framework wherein the parametric controllers decide the GNN architecture for each node based on its local patterns. We instantiate our framework with depth, aggregator and resolution controllers, and then elaborate on learning the backbone GNN model and the controllers to encourage their cooperation. Empirically, we justify the effects of node-wise architecture through the performance improvements introduced by the three controllers, respectively. Moreover, our proposed framework significantly outperforms state-of-the-art methods on five of the ten real-world datasets, where the diversity of these datasets has hindered any graph convolution-based method to lead on them simultaneously. This result further confirms that node-wise architecture can help GNNs become versatile models.
@inproceedings{nw-gnn, dimensions = {true}, author = {Wang, Zhen and Wei, Zhewei and Li, Yaliang and Kuang, Weirui and Ding, Bolin}, title = {Graph Neural Networks with Node-wise Architecture}, year = {2022}, isbn = {9781450393850}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3534678.3539387}, doi = {10.1145/3534678.3539387}, booktitle = {Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}, pages = {1949–1958}, numpages = {10}, keywords = {dynamic neural networks, graph neural networks, neural architecture search}, location = {Washington DC, USA}, series = {KDD '22} } - FS-GNN
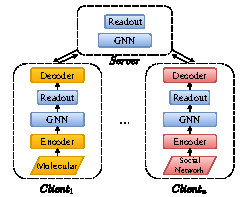 FederatedScope-GNN: Towards a Unified, Comprehensive and Efficient Package for Federated Graph LearningZhen Wang, Weirui Kuang, Yuexiang Xie, Liuyi Yao, and 3 more authorsIn Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington DC, USA. ADS Track Best Paper Award. , Apr 2022
FederatedScope-GNN: Towards a Unified, Comprehensive and Efficient Package for Federated Graph LearningZhen Wang, Weirui Kuang, Yuexiang Xie, Liuyi Yao, and 3 more authorsIn Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington DC, USA. ADS Track Best Paper Award. , Apr 2022The incredible development of federated learning (FL) has benefited various tasks in the domains of computer vision and natural language processing, and the existing frameworks such as TFF and FATE has made the deployment easy in real-world applications. However, federated graph learning (FGL), even though graph data are prevalent, has not been well supported due to its unique characteristics and requirements. The lack of FGL-related framework increases the efforts for accomplishing reproducible research and deploying in real-world applications. Motivated by such strong demand, in this paper, we first discuss the challenges in creating an easy-to-use FGL package and accordingly present our implemented package FederatedScope-GNN (FS-G), which provides (1) a unified view for modularizing and expressing FGL algorithms; (2) comprehensive DataZoo and ModelZoo for out-of-the-box FGL capability; (3) an efficient model auto-tuning component; and (4) off-the-shelf privacy attack and defense abilities. We validate the effectiveness of FS-G by conducting extensive experiments, which simultaneously gains many valuable insights about FGL for the community. Moreover, we employ FS-G to serve the FGL application in real-world E-commerce scenarios, where the attained improvements indicate great potential business benefits. We publicly release FS-G, as submodules of FederatedScope, at https://github.com/alibaba/FederatedScope to promote FGL’s research and enable broad applications that would otherwise be infeasible due to the lack of a dedicated package.
@inproceedings{FSGNN, dimensions = {true}, title = {FederatedScope-GNN: Towards a Unified, Comprehensive and Efficient Package for Federated Graph Learning}, url = {https://doi.org/10.1145/3534678.3539112}, doi = {10.1145/3534678.3539112}, year = {2022}, author = {Wang, Zhen and Kuang, Weirui and Xie, Yuexiang and Yao, Liuyi and Li, Yaliang and Ding, Bolin and Zhou, Jingren}, isbn = {9781450393850}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, booktitle = {Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}, pages = {4110–4120}, numpages = {11}, keywords = {federated learning, graph neural networks}, location = {Washington DC, USA}, series = {KDD '22} } - EvenNet
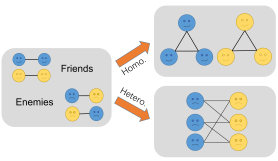 EvenNet: Ignoring Odd-Hop Neighbors Improves Robustness of Graph Neural NetworksRunlin Lei, Zhen Wang, Yaliang Li, Bolin Ding, and 1 more authorIn Advances in Neural Information Processing Systems, Apr 2022
EvenNet: Ignoring Odd-Hop Neighbors Improves Robustness of Graph Neural NetworksRunlin Lei, Zhen Wang, Yaliang Li, Bolin Ding, and 1 more authorIn Advances in Neural Information Processing Systems, Apr 2022Graph Neural Networks (GNNs) have received extensive research attention for their promising performance in graph machine learning. Despite their extraordinary predictive accuracy, existing approaches, such as GCN and GPRGNN, are not robust in the face of homophily changes on test graphs, rendering these models vulnerable to graph structural attacks and with limited capacity in generalizing to graphs of varied homophily levels. Although many methods have been proposed to improve the robustness of GNN models, most of these techniques are restricted to the spatial domain and employ complicated defense mechanisms, such as learning new graph structures or calculating edge attentions. In this paper, we study the problem of designing simple and robust GNN models in the spectral domain. We propose EvenNet, a spectral GNN corresponding to an even-polynomial graph filter. Based on our theoretical analysis in both spatial and spectral domains, we demonstrate that EvenNet outperforms full-order models in generalizing across homophilic and heterophilic graphs, implying that ignoring odd-hop neighbors improves the robustness of GNNs. We conduct experiments on both synthetic and real-world datasets to demonstrate the effectiveness of EvenNet. Notably, EvenNet outperforms existing defense models against structural attacks without introducing additional computational costs and maintains competitiveness in traditional node classification tasks on homophilic and heterophilic graphs.
@inproceedings{EvenNet, dimensions = {true}, author = {Lei, Runlin and Wang, Zhen and Li, Yaliang and Ding, Bolin and Wei, Zhewei}, booktitle = {Advances in Neural Information Processing Systems}, editor = {Koyejo, S. and Mohamed, S. and Agarwal, A. and Belgrave, D. and Cho, K. and Oh, A.}, pages = {4694--4706}, publisher = {Curran Associates, Inc.}, title = {EvenNet: Ignoring Odd-Hop Neighbors Improves Robustness of Graph Neural Networks}, url = {https://proceedings.neurips.cc/paper_files/paper/2022/file/1e62dae07279cb09d2e87378d10dacfc-Paper-Conference.pdf}, volume = {35}, year = {2022} } - iFloodiFlood: A Stable and Effective RegularizerYuexiang Xie, Zhen WANG, Yaliang Li, Ce Zhang, and 2 more authorsIn International Conference on Learning Representations, Apr 2022
Various regularization methods have been designed to prevent overfitting of machine learning models. Among them, a surprisingly simple yet effective one, called Flooding, is proposed recently, which directly constrains the training loss on average to stay at a given level. However, our further studies uncover that the design of the loss function of Flooding can lead to a discrepancy between its objective and implementation, and cause the instability issue. To resolve these issues, in this paper, we propose a new regularizer, called individual Flood (denoted as iFlood). With instance-level constraints on training loss, iFlood encourages the trained models to better fit the under-fitted instances while suppressing the confidence on over-fitted ones. We theoretically show that the design of iFlood can be intrinsically connected with removing the noise or bias in training data, which makes it suitable for a variety of applications to improve the generalization performances of learned models. We also theoretically link iFlood to some other regularizers by comparing the inductive biases they introduce. Our experimental results on both image classification and language understanding tasks confirm that models learned with iFlood can stably converge to solutions with better generalization ability, and behave consistently at instance-level.
@inproceedings{iFlood, dimensions = {true}, title = {iFlood: A Stable and Effective Regularizer}, author = {Xie, Yuexiang and WANG, Zhen and Li, Yaliang and Zhang, Ce and Zhou, Jingren and Ding, Bolin}, booktitle = {International Conference on Learning Representations}, year = {2022}, url = {https://openreview.net/forum?id=MsHnJPaBUZE} }
2021
- FIVES
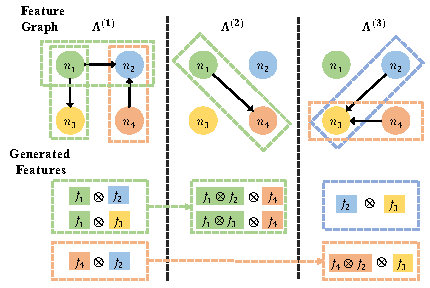 FIVES: Feature Interaction Via Edge Search for Large-Scale Tabular DataYuexiang Xie*, Zhen Wang*, Yaliang Li, Bolin Ding, and 5 more authorsIn Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, Singapore, Apr 2021* Equal contribution
FIVES: Feature Interaction Via Edge Search for Large-Scale Tabular DataYuexiang Xie*, Zhen Wang*, Yaliang Li, Bolin Ding, and 5 more authorsIn Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, Singapore, Apr 2021* Equal contributionHigh-order interactive features capture the correlation between different columns and thus are promising to enhance various learning tasks on ubiquitous tabular data. To automate the generation of interactive features, existing works either explicitly traverse the feature space or implicitly express the interactions via intermediate activations of some designed models. These two kinds of methods show that there is essentially a trade-off between feature interpretability and search efficiency. To possess both of their merits, we propose a novel method named Feature Interaction Via Edge Search (FIVES), which formulates the task of interactive feature generation as searching for edges on the defined feature graph. Specifically, we first present our theoretical evidence that motivates us to search for useful interactive features with increasing order. Then we instantiate this search strategy by optimizing both a dedicated graph neural network (GNN) and the adjacency tensor associated with the defined feature graph. In this way, the proposed FIVES method simplifies the time-consuming traversal as a typical training course of GNN and enables explicit feature generation according to the learned adjacency tensor. Experimental results on both benchmark and real-world datasets show the advantages of FIVES over several state-of-the-art methods. Moreover, the interactive features identified by FIVES are deployed on the recommender system of Taobao, a worldwide leading e-commerce platform. Results of an online A/B testing further verify the effectiveness of the proposed method FIVES, and we further provide FIVES as AI utilities for the customers of Alibaba Cloud.
@inproceedings{FIVES, dimensions = {true}, note = {* Equal contribution}, author = {Xie, Yuexiang and Wang, Zhen and Li, Yaliang and Ding, Bolin and G\"{u}rel, Nezihe Merve and Zhang, Ce and Huang, Minlie and Lin, Wei and Zhou, Jingren}, title = {FIVES: Feature Interaction Via Edge Search for Large-Scale Tabular Data}, year = {2021}, isbn = {9781450383325}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3447548.3467066}, doi = {10.1145/3447548.3467066}, booktitle = {Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery \& Data Mining}, pages = {3795–3805}, numpages = {11}, keywords = {automated machine learning, feature graph, feature interaction}, location = {Virtual Event, Singapore}, series = {KDD '21} }
2014
- KATEKnowledge graph and text jointly embeddingZhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng ChenIn Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), Apr 2014
We examine the embedding approach to reason new relational facts from a largescale knowledge graph and a text corpus. We propose a novel method of jointly embedding entities and words into the same continuous vector space. The embedding process attempts to preserve the relations between entities in the knowledge graph and the concurrences of words in the text corpus. Entity names and Wikipedia anchors are utilized to align the embeddings of entities and words in the same space. Large scale experiments on Freebase and a Wikipedia/NY Times corpus show that jointly embedding brings promising improvement in the accuracy of predicting facts, compared to separately embedding knowledge graphs and text. Particularly, jointly embedding enables the prediction of facts containing entities out of the knowledge graph, which cannot be handled by previous embedding methods. At the same time, concerning the quality of the word embeddings, experiments on the analogical reasoning task show that jointly embedding is comparable to or slightly better than word2vec (Skip-Gram).
@inproceedings{KATE, dimensions = {true}, title = {Knowledge graph and text jointly embedding}, author = {Wang, Zhen and Zhang, Jianwen and Feng, Jianlin and Chen, Zheng}, booktitle = {Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP)}, pages = {1591--1601}, year = {2014} } - TransH
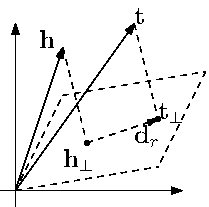 Knowledge Graph Embedding by Translating on HyperplanesZhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng ChenProceedings of the AAAI Conference on Artificial Intelligence, Jun 2014
Knowledge Graph Embedding by Translating on HyperplanesZhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng ChenProceedings of the AAAI Conference on Artificial Intelligence, Jun 2014We deal with embedding a large scale knowledge graph composed of entities and relations into a continuous vector space. TransE is a promising method proposed recently, which is very efficient while achieving state-of-the-art predictive performance. We discuss some mapping properties of relations which should be considered in embedding, such as reflexive, one-to-many, many-to-one, and many-to-many. We note that TransE does not do well in dealing with these properties. Some complex models are capable of preserving these mapping properties but sacrifice efficiency in the process. To make a good trade-off between model capacity and efficiency, in this paper we propose TransH which models a relation as a hyperplane together with a translation operation on it. In this way, we can well preserve the above mapping properties of relations with almost the same model complexity of TransE. Additionally, as a practical knowledge graph is often far from completed, how to construct negative examples to reduce false negative labels in training is very important. Utilizing the one-to-many/many-to-one mapping property of a relation, we propose a simple trick to reduce the possibility of false negative labeling. We conduct extensive experiments on link prediction, triplet classification and fact extraction on benchmark datasets like WordNet and Freebase. Experiments show TransH delivers significant improvements over TransE on predictive accuracy with comparable capability to scale up.
@article{TransH, dimensions = {true}, title = {Knowledge Graph Embedding by Translating on Hyperplanes}, volume = {28}, url = {https://ojs.aaai.org/index.php/AAAI/article/view/8870}, doi = {10.1609/aaai.v28i1.8870}, number = {1}, journal = {Proceedings of the AAAI Conference on Artificial Intelligence}, author = {Wang, Zhen and Zhang, Jianwen and Feng, Jianlin and Chen, Zheng}, year = {2014}, month = jun }